改进物元可拓法
方法概述
改进物元可拓法是在传统物元可拓模型基础上,针对量纲影响和关联函数计算复杂的问题所提出的优化方法。主要改进点包括:
- 归一化处理:对所有指标的实测值和经典域区间进行归一化,消除量纲差异,使不同指标具有可比性。
- 贴近度代替关联函数:采用改进的贴近度公式计算各等级的综合隶属程度,避免了传统关联函数中分母为零等不稳定情况。
- 等级变量特征值:引入标准化贴近度和等级变量特征值(等级序号的加权平均值),可实现评价对象之间的精细排序。
该方法适用于质量评价、风险评估、环境监测、工程方案比选等领域,尤其适合等级划分明确、需要排序比较的评价问题。
计算步骤
1. 数据准备
设有 \(n\) 个评价指标,\(m\) 个评价等级。数据文件格式如下(每行对应一个指标):
| 指标名称 | 权重 | 实测值 | 等级1_下限 | 等级1_上限 | 等级2_下限 | 等级2_上限 | … | 节域下限 | 节域上限 |
|---|
- 第一列:指标名称。
- 第二列:指标权重(需满足 \(\sum w_i = 1\))。
- 第三列:待评价对象的指标实测值 \(x_i\)。
- 后续列:每两列为一组,分别表示某个等级的下限和上限(如“优_下限”、“优_上限”)。列名格式为“等级名称_下限”和“等级名称_上限”。等级列的顺序即为等级序号 1,2,…,m,用于计算等级变量特征值。
- 最后两列:节域下限和节域上限,表示该指标所有可能取值的范围(应包含所有经典域)。
2. 归一化
为了消除量纲影响,将所有指标实测值和经典域区间统一映射到 \([0,1]\) 区间。
设节域为 \([a_p, b_p]\),则指标实测值 \(x\) 的归一化值为: \[ x' = \frac{x - a_p}{b_p - a_p} \]
对于经典域区间 \(V_{jk} = [a_{jk}, b_{jk}]\),归一化后为: \[ V'_{jk} = \left[ \frac{a_{jk} - a_p}{b_p - a_p},\ \frac{b_{jk} - a_p}{b_p - a_p} \right] \]
3. 计算点到区间的距离(距)
对于归一化后的点 \(x'\) 和区间 \(V' = [a', b']\),定义距离: \[ \rho(x', V') = \left| x' - \frac{a'+b'}{2} \right| - \frac{b'-a'}{2} \]
该距离可正可负:当 \(x'\) 在区间内时 \(\rho \le 0\),在区间外时 \(\rho > 0\)。
4. 计算综合加权距离
设共有 \(n\) 个底层指标,指标 \(i\) 的权重为 \(w_i\),归一化后到等级 \(j\) 经典域的距离为 \(\rho_{ij}\),则等级 \(j\) 的加权总距离为: \[ D_j = \sum_{i=1}^{n} w_i \cdot \rho_{ij} \]
5. 计算贴近度
贴近度 \(T_j\) 表示评价对象隶属于等级 \(j\) 的程度,值越大隶属度越高。计算公式为: \[ T_j = 1 - \frac{1}{n(n+1)} \cdot D_j \]
其中 \(n\) 为底层指标个数(当采用多层次结构时,\(n\) 为最底层指标个数)。该公式保证了 \(T_j\) 在 \([0,1]\) 范围内。
6. 标准化贴近度与等级变量特征值
(1)标准化贴近度:对各等级的贴近度向量进行最小-最大标准化,得到标准化贴近度 \(S_j\): \[ S_j = \frac{T_j - \min\limits_{k} T_k}{\max\limits_{k} T_k - \min\limits_{k} T_k} \]
(2)等级变量特征值:利用等级序号 \(j=1,2,\dots,m\) 作为位置标尺,计算加权平均: \[ j^* = \frac{\sum_{j=1}^{m} j \cdot S_j}{\sum_{j=1}^{m} S_j} \]
\(j^*\) 是一个介于 1 和 \(m\) 之间的实数值,可用于不同评价对象之间的精确排序。值越靠近哪个等级序号,表示更倾向于该等级。
7. 等级判定
最大贴近度对应的等级为最终评价等级: \[ j_{\text{final}} = \arg\max_{j} T_j \]
8. 多层次结构(可选)
系统支持最多 5 层的指标体系。底层指标计算距矩阵后,按照用户定义的聚合关系向上层传递。上层指标的距值为其包含的下层指标距值的加权和(权重为各下层指标的原始权重之和)。最终顶层指标的加权总距按相同公式计算贴近度和特征值。
案例分析
案例背景:某产品环境友好性评价,选取 3 个指标:污染物排放(成本型)、资源消耗(成本型)、绿色创新(效益型)。评价等级设为“优”、“良”、“中”、“差”。数据如下(经典域和节域已按行业标准设定):
| 指标名称 | 权重 | 实测值 | 优_下限 | 优_上限 | 良_下限 | 良_上限 | 中_下限 | 中_上限 | 差_下限 | 差_上限 | 节域下限 | 节域上限 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 污染物排放 | 0.4 | 25 | 0 | 20 | 20 | 40 | 40 | 60 | 60 | 100 | 0 | 100 |
| 资源消耗 | 0.3 | 55 | 0 | 30 | 30 | 50 | 50 | 70 | 70 | 100 | 0 | 100 |
| 绿色创新 | 0.3 | 80 | 90 | 100 | 70 | 90 | 50 | 70 | 0 | 50 | 0 | 100 |
改进法计算过程
1. 归一化
节域均为 \([0,100]\),归一化公式为 \(x' = x/100\)。归一化后的数据:
| 指标 | 实测值归一化 | 优区间 | 良区间 | 中区间 | 差区间 |
|---|---|---|---|---|---|
| 污染物排放 | 0.25 | [0, 0.2] | [0.2, 0.4] | [0.4, 0.6] | [0.6, 1] |
| 资源消耗 | 0.55 | [0, 0.3] | [0.3, 0.5] | [0.5, 0.7] | [0.7, 1] |
| 绿色创新 | 0.80 | [0.9, 1] | [0.7, 0.9] | [0.5, 0.7] | [0, 0.5] |
2. 计算距 \(\rho\)
以污染物排放(\(x'=0.25\))为例: - 优区间 \([0,0.2]\):\(\rho = |0.25-0.1| - 0.1 = 0.15 - 0.1 = 0.05\) - 良区间 \([0.2,0.4]\):\(\rho = |0.25-0.3| - 0.1 = 0.05 - 0.1 = -0.05\) - 中区间 \([0.4,0.6]\):\(\rho = |0.25-0.5| - 0.1 = 0.25 - 0.1 = 0.15\) - 差区间 \([0.6,1]\):\(\rho = |0.25-0.8| - 0.2 = 0.55 - 0.2 = 0.35\)
类似计算其他指标(略),得到距矩阵:
| 指标 | 优距 \(\rho\) | 良距 \(\rho\) | 中距 \(\rho\) | 差距 \(\rho\) |
|---|---|---|---|---|
| 污染物排放 | 0.05 | -0.05 | 0.15 | 0.35 |
| 资源消耗 | 0.25 | 0.05 | -0.05 | 0.15 |
| 绿色创新 | 0.10 | -0.10 | -0.10 | 0.30 |
3. 计算加权总距 \(D_j\)
权重分别为 0.4, 0.3, 0.3: - 优:\(0.4\times0.05 + 0.3\times0.25 + 0.3\times0.10 = 0.02 + 0.075 + 0.03 = 0.125\) - 良:\(0.4\times(-0.05) + 0.3\times0.05 + 0.3\times(-0.10) = -0.02 + 0.015 - 0.03 = -0.035\) - 中:\(0.4\times0.15 + 0.3\times(-0.05) + 0.3\times(-0.10) = 0.06 - 0.015 - 0.03 = 0.015\) - 差:\(0.4\times0.35 + 0.3\times0.15 + 0.3\times0.30 = 0.14 + 0.045 + 0.09 = 0.275\)
4. 计算贴近度 \(T_j\)
底层指标个数 \(n=3\),分母 \(n(n+1)=12\): - 优:\(T = 1 - \frac{1}{12}\times0.125 = 1 - 0.01042 = 0.9896\) - 良:\(T = 1 - \frac{1}{12}\times(-0.035) = 1 + 0.00292 = 1.0029\)(注:由于距可为负,贴近度可能略大于1,此时取1处理,实际应用中可限制在 \([0,1]\)) - 中:\(T = 1 - \frac{1}{12}\times0.015 = 1 - 0.00125 = 0.9988\) - 差:\(T = 1 - \frac{1}{12}\times0.275 = 1 - 0.02292 = 0.9771\)
修正后贴近度向量:\([0.9896, 1.0000, 0.9988, 0.9771]\)
5. 标准化贴近度与等级变量特征值
标准化(最小=0.9771,最大=1.0000): - 优:\((0.9896-0.9771)/(0.0229)=0.0125/0.0229=0.5459\) - 良:\((1.0000-0.9771)/0.0229=0.0229/0.0229=1.0000\) - 中:\((0.9988-0.9771)/0.0229=0.0217/0.0229=0.9476\) - 差:\((0.9771-0.9771)/0.0229=0\)
等级序号:优=1,良=2,中=3,差=4。计算特征值: \[ j^* = \frac{1\times0.5459 + 2\times1.0000 + 3\times0.9476 + 4\times0}{0.5459+1.0000+0.9476+0} = \frac{0.5459+2.0000+2.8428}{2.4935} = \frac{5.3887}{2.4935} \approx 2.16 \]
6. 等级判定
最大贴近度为 1.0000,对应“良”等级,与原始判断一致。等级变量特征值 2.16 表明综合评价结果介于良(等级2)与中(等级3)之间,更偏向良等级。
结论:该产品的环境友好性综合评价等级为“良”。等级特征值 2.16 可用于与其他产品进行数值比较。
常见问题
Q1: 改进物元可拓法与经典物元可拓法的主要区别是什么?
A: 主要区别有三:①增加归一化步骤,消除量纲影响;②使用贴近度 \(T_j = 1 - D_j/[n(n+1)]\) 替代传统关联函数,计算更稳定,结果始终在 \([0,1]\) 区间(除个别负数距导致的略超);③提供等级变量特征值,实现评价对象的连续排序,弥补等级离散性的不足。
Q2: 经典域和节域如何设定?
A: 经典域由行业标准或专家经验确定,每个等级对应一个区间。节域需包含所有经典域,通常取所有经典域下限的最小值到上限的最大值。注意成本型指标和效益型指标的区间方向(成本型越小越优,效益型越大越优),在数据表中直接按数值大小填写对应等级的上下限即可。
Q3: 多层次结构如何配置?
A: 在界面中设置层级数(1~5层),然后为每一层(除底层外)指定上层指标的名称及其包含的下层指标。系统会自动聚合并计算各层的距矩阵和贴近度,最终得到顶层综合评价。
Q4: 等级变量特征值的意义是什么?
A: 特征值 \(j^*\) 是对标准化贴近度的加权平均,取值范围在 \([1, m]\) 之间。它反映了评价对象在等级序列上的“重心”位置,可对不同对象进行精细排序。例如,两个对象都评为“良”级,但特征值分别为 2.1 和 2.8,则前者更接近“优”,后者更接近“中”,前者综合表现更优。
Q5: 权重和不为1时如何处理?
A: 平台会给出警告,但不会自动归一化。用户应确保权重和严格为 1,否则可能影响距的加权计算结果。
Q6: 支持多工作表吗?
A: 支持。Excel 文件中的每个工作表视为一个独立的评价任务,系统会分别分析并输出所有结果。
平台功能
改进物元可拓法分析平台提供以下核心功能:
数据输入
- 支持 Excel(.xlsx, .xls)格式,每个工作表为一个物元数据矩阵。
- 自动检测评价等级(通过列名中的“_下限”“_上限”后缀识别)、节域(最后两列)、指标权重和实测值。
参数设置
- 小数位数:控制结果精度(默认 4 位)。
- 层次结构层数:可设置 1~5 层,配置上层指标的名称及其包含的下层指标(支持多选)。
- 自动显示检测到的等级列表和节域信息。
结果展示
- 综合评价结果:最终评价等级、最大贴近度、等级变量特征值。
- 综合贴近度:各等级的贴近度值和标准化贴近度值。
- 底层指标评价结果:每个指标的权重、得分、距值、等级判断。
- 详细计算过程:归一化后的数据、距矩阵、加权总距等。
- 多层次分析(若启用):显示层次结构配置、各层次指标的计算结果(距、等级判断)。
- 可视化:各等级贴近度柱状图、多层次综合贴近度图。
- AI 智能分析:基于 DeepSeek API 自动解读结果,提供改进建议(每日限 3 次)。
- 多格式导出:支持 Excel 和 HTML 报告下载。
使用建议
准备阶段:明确评价指标体系,确定评价等级(通常 3~5 个)。根据标准或专家经验确定每个指标在各等级下的经典域区间(注意成本型与效益型的区间方向),以及所有指标的整体节域。
数据收集:使用平台提供的模板文件填写数据。确保列名格式为“等级名称_下限”和“等级名称_上限”,最后两列为节域。权重列和为 1,实测值必须落在节域内。等级列的顺序将直接影响等级变量特征值的含义(通常按优劣顺序排列)。
参数设置:若指标体系复杂,可设置多层次结构。层次数不宜过多,一般 2~3 层即可。
结果解读:
- 最终等级反映整体水平。
- 观察底层指标距值(或等级判断)可识别短板指标。
- 等级变量特征值用于精确排序,可比较同等级或多个评价对象的细微差异。
- 利用 AI 分析可快速获得专业解读和改进方向。
迭代优化:若结果与预期不符,检查经典域、节域设置是否合理,调整权重或重新归一化。对比不同工作表的分析结果,辅助方案优选。
平台界面
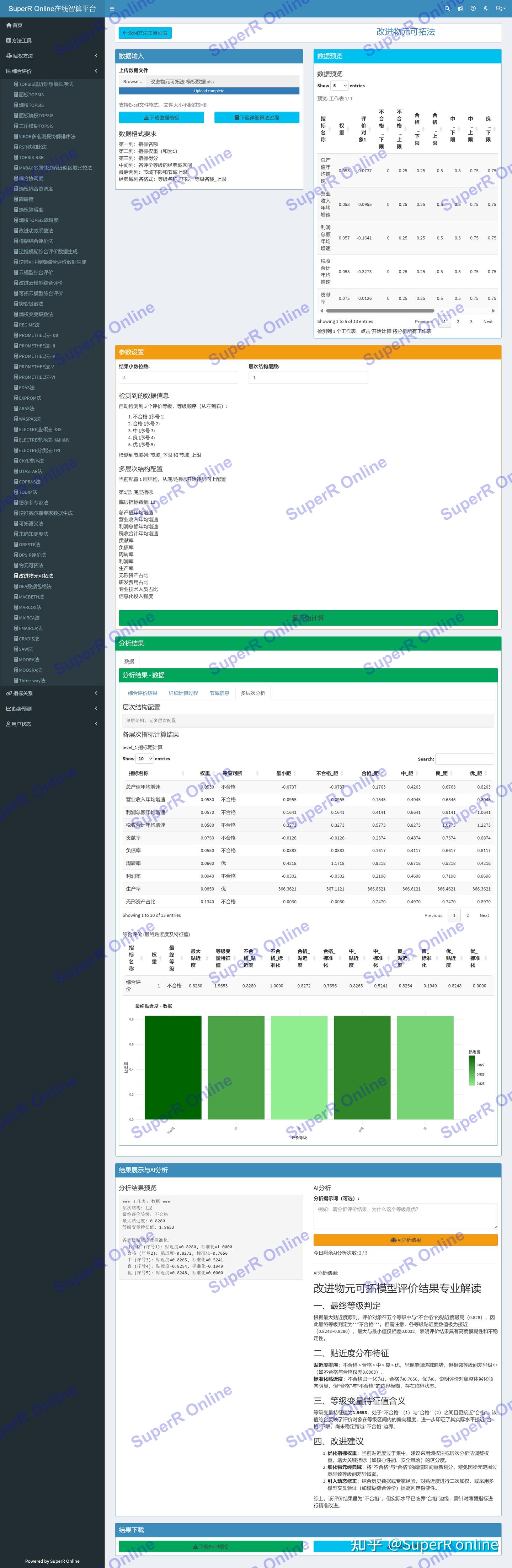
平台界面包含:数据上传区、参数设置区、多工作表预览、分析结果展示和AI分析模块
参考文献:
- 蔡文. 可拓集合和不相容问题[J]. 科学探索学报,1983(1): 83-97.
- 杨春燕,蔡文. 可拓工程方法[M]. 科学出版社,2017.
- 基于改进物元可拓模型的区域水资源承载力评价[J]. 水利学报,2020, 51(2): 156-164.